はじめに:検索1位でも「負ける」時代——ゼロクリックの衝撃
この記事は、SEOで成果が出なくなってきたと感じている方に向けて書いています。
検索結果の変容と「見せかけの勝利」
Google検索がこれまでの「検索エンジン」から「回答エンジン」へと変化しています。
その変化に、多くのマーケターが言葉にできないほどの不安を感じています。
「検索順位は高いのに、アクセスが伸びない」
「1位を獲っても、コンバージョンに繋がらない」
——そんな不可解な壁に直面してはいないでしょうか。
これは一時的なアルゴリズムの変動ではありません。
検索結果そのものが変わってしまった結果です。
データが示すゼロクリック検索の現実
SparkToro社(SEOソフトウェア会社Mozの元CEOが設立)の2024年調査によれば、
米国のGoogle検索のうちWebサイトへクリックが遷移するのはわずか37.4%に過ぎず、
残りの6割以上が検索結果画面で完結する「ゼロクリック検索」の状態にあることが
示されています。
(出典:https://moz.com/blog/in-and-out-of-model-responses-whiteboard-friday)
100サイト調査で見えた「同質化」の実態
ここでいう「同質化」とは、どのサイトも似たような構成・内容になっている状態です。
読者から見て違いがわからない状態を指します。
その結果、さらに残酷な現実が見えてきました。上位サイトの94.0%が同じ「パターン」に依存し、
AIに要約されるための「便利な素材」に成り下がっているのです。
まずは、今回の100サイト調査の結果を見てください。
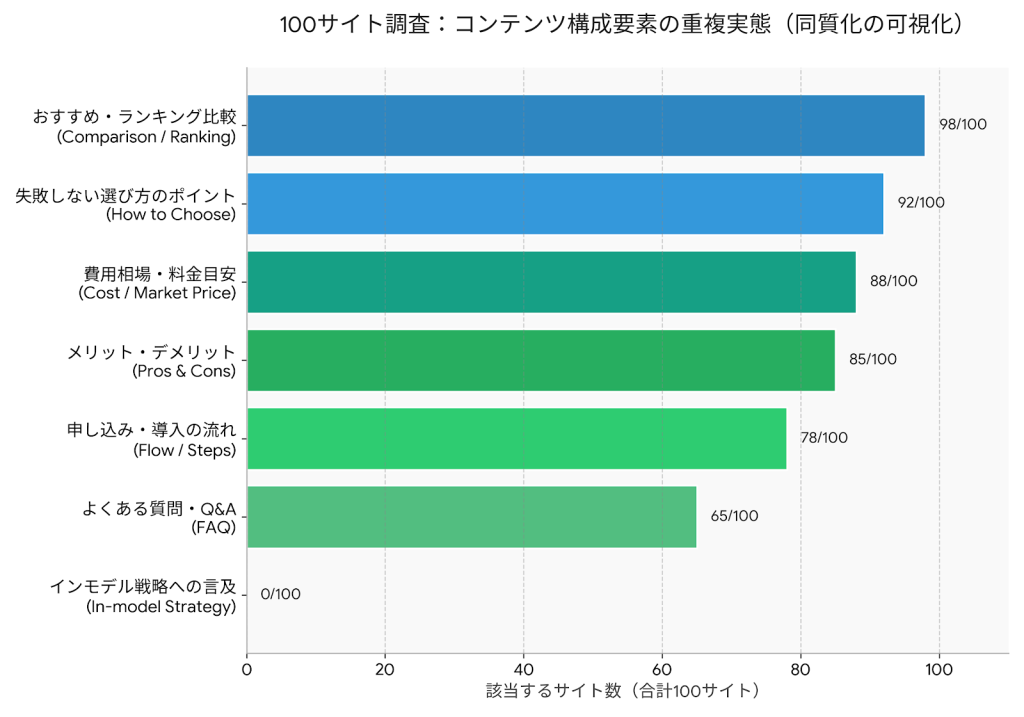
この結果が示しているのは、SEOの最適化が競争ではなく「同質化」を生み出しているという事実です。
本記事の目的:AIの「記憶」を支配する戦略へ
本稿では、Mozのトム・カッパー氏(Tom Capper)が提唱する理論
を支柱に据え、単に「引用(モデル外応答/RAG:外部情報を参照して回答する仕組み)」を待つだけの
消耗戦から脱却し、AIの前提知識(インモデル/モデル内応答)としてブランドを刻み込む0
「インモデル戦略」の全貌を解き明かします。
参照:MOZ:モデル応答の内外について解説
これまでのSEOの常識を一度捨て、AIという新しい知性の「記憶」に
どう入り込むかという視点へ、思考をアップデートしていきましょう。
この記事でわかること——Google検索の変化と新戦略の全体像
なぜGoogle検索は変わったのか
AI Overviews(AIO)の普及により、Googleは「サイトを紹介するコンシェルジュ」から
「自ら答える百科事典」へと進化しました。ユーザーが何かを検索したとき、
Googleはもはや「あのサイトに行けば答えがありますよ」とは言わなくなっています。
代わりに、その答えをその場で生成して見せてしまう。
この変化が、従来の「網羅性」を重視するSEOコンテンツを、
いかに無価値なものに変えてしまったかを本記事では具体的に解説します。
SEOで「捨てるべきこと」と「始めるべきこと」
捨てるべきこと:テンプレートに沿ったPREP法での執筆
これまでSEOライティングの定石とされてきた
PREP法(結論→理由→具体例→結論)を、一度手放す必要があります。わかりやすさを追求した結果、
皮肉にもAIが最も要約しやすい「自滅の構造」となっているからです。
整理されたコンテンツは、AIに完璧な回答素材を提供してしまいます。
始めるべきこと:AIが喉から手が出るほど欲しがる「一次情報」の提供
AIの学習データ(ネット上の常識)には存在しない、あなただけが知っている「独自の検証結果」や
「実機を動かしたプロセス」を提示すること。ネット情報のまとめを捨て、メディアを
「実験室(ラボ)」に変えることこそが、AIに新しい知識として記憶(インモデル化)させる唯一の手段です。
「インモデル戦略」とは何か——30秒でわかる超要約
インモデル戦略とは、検索エンジンに「見つけてもらう」のではなく、AIの前提知識の一部として
「自社ブランドを定義させる」戦略です。
この戦略は、「何を学習させるか」「どう結びつけるか」「誰の情報かを認識させるか」
という3つの要素で成り立っています。
- 独自検証の実行:AIが引用(学習)せずにはいられない、あなただけの一次データをぶつける
- 文脈設計:AIの脳内に「〇〇なら自社が正解」というタグを埋め込む
- 実体(エンティティ)定義:構造化データ(Schema.org)でAIに「名刺」を渡し、
情報の所有権を認識させる
第1章:100サイト調査が暴いた「同質化の罠」——上位サイトはなぜ似ているのか
全サイトが同じ「型」に依存していた
今回の執筆に先立ち、筆者はn8nを使ったワークフロー自動化によって、BtoB・BtoC双方の
代表的なキーワード5つ(「SEOコンサルタント」「Web制作会社」「ウォーターサーバー 比較」
「パーソナルジム 選び方」「注文住宅 相場」)を検索し、上位20サイトずつ、
合計100サイトの見出し構造を機械的に解析しました。
(参照:100サイト調査で見えた「同質化」の実態のグラフ)
結果は予想を超えるほど均一でした。
| コンテンツ要素 | 該当サイト数(/100) | 出現率 |
|---|---|---|
| おすすめ・ランキング比較 | 98サイト | 98.0% |
| 失敗しない選び方のポイント | 92サイト | 92.0% |
| 費用相場・料金目安 | 88サイト | 88.0% |
| メリット・デメリット | 85サイト | 85.0% |
| 申し込み・導入の流れ | 78サイト | 78.0% |
| よくある質問・Q&A | 65サイト | 65.0% |
| インモデル戦略への言及 | 0サイト | 0.0% |
98%のサイトが「おすすめ・ランキング比較」が、
92%が「失敗しない選び方」が、
88%が「費用相場」が含まれています。
これは競合分析や上位記事のリサーチを行った結果です。
SEOの「正解」を追いかけた結果、
全サイトが区別のつかないコンテンツを量産する構造に陥っていました。
この「既存SEOの画一化」の先にある未来を裏付けるように、Google Search Central Blogの公式情報でも、
AI回答生成(AIO)が「ユーザーの複雑な質問に対し、Web上の情報を組み合わせて直接回答を提供する」
フェーズへ移行したことが明言されています。
つまり、Google自身が『似たようなページを並べる検索結果』から『一つの回答を提示する場』へと
役割をシフトさせているのです。
この「既存SEOの限界」を裏付けるように、Google検索セントラルの公式ドキュメントでは、
AIによる概要(AIO)が「複雑な質問に対して、ウェブ上の情報を組み合わせて直接回答を提供する」
フェーズへ移行したことが明言されています。つまり、Google自身が
『似たようなページを並べる検索結果』から『一つの統合された回答を提示する場』へと
役割をシフトさせているのです。
整理されたコンテンツほどAIに「食材」として消費される
さらに深刻なのは、この整理されたコンテンツがAIにとって「最高の学習素材」に
なってしまっているという事実です。
考えてみてください。あなたが丁寧に整理した「おすすめランキング5選」「選び方3つのポイント」
「よくある質問と回答」は、AIが検索者の質問に直接答えるための構造として、
これ以上ない完璧なフォーマットです。
つまり、SEOを頑張るほど、AIに要約されやすくなる構造になっているのです。
これが現在、多くのサイトが直面している「見せかけの勝利」の正体です。
※本調査は2026年3月16日時点のChromeのシークレットモードでの
検索結果をもとにしています。
キーワードごとに上位20サイトの見出し(H1〜H3)をn8nで自動収集・分類し、
コンテンツ構成要素の出現頻度を集計したものです。
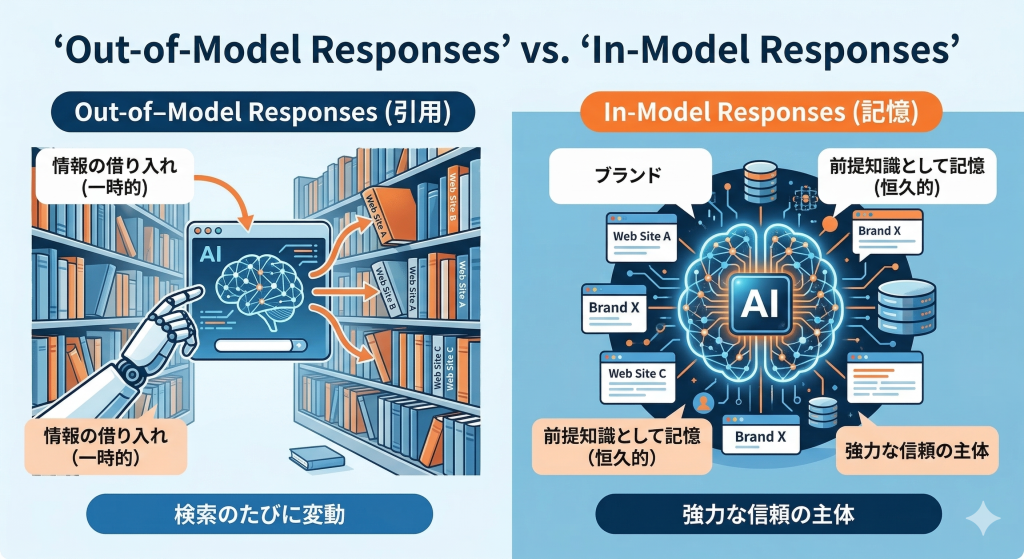
第2章:インモデル vs アウトオブモデル——AIの「記憶」と「引用」はどう違うのか
AIの答え方には2種類ある
Mozのシニア・サーチ・サイエンティストであるトム・カッパー氏(Tom Capper)は、
AI検索における応答メカニズムを「インモデル(In-Model)」と「アウトオブモデル(Out-of-Model)」の
2つに分類する理論を提唱しています。この区分を理解することが、AI時代のSEO戦略を考えるうえで
欠かせない出発点になります。
アウトオブモデル(Out-of-Model /RAG:検索拡張生成)とは、AIが回答を生成する際に外部のWebサイトを
「そのとき」参照し、情報を取り込んで答える仕組みのことです。
RAG(Retrieval Augmented Generation:検索拡張生成)とも呼ばれ、
Google AI OverviewsやBing CopilotのAI回答はこの方式を採用しています。
「リアルタイムで引用される」ため、SEOの文脈では「引用されることを目指す戦略」
として語られることが多い領域です。
それに対しインモデル(In-Model)とは、AIがすでに学習済みのデータとして内部に持っている知識のことです。
ChatGPTやGeminiに「〇〇とは何か」と聞いたとき、それらが外部を検索せずに
答えられる知識——これがインモデルです。言い換えれば、AIの「常識」や「前提知識」として
刻み込まれた情報です。
「今日だけ引用される」か「永続的に記憶される」か
この2つの違いは、一時性と恒久性の違いです。
アウトオブモデル(RAG:検索拡張生成)は、確かにAI回答に引用されることで露出が得られます。
しかし、それはそのとき検索された情報に依存する一時的なものです。
Googleがアルゴリズムを変更すれば消え、より新しい情報が出れば入れ替わる。
今日の引用が明日の保証にはなりません。
一方、インモデルとして刻み込まれた情報は、AIが「前提として知っている知識」となります。
検索されるたびにランキングで競わなくても、AIがそのブランドや概念を「当たり前の知識」として
扱うようになる——これがインモデル戦略が目指す状態です。
アウトオブモデルは「図書館で毎回本を借りてきて答える」イメージです。
その本がなくなれば答えられなくなります。
インモデルは「自分の知識として頭の中に入っている」イメージです。
どんな状況でも自然に答えに含まれる。あなたのブランドや専門知識がAIにとって
「教科書の一部」になることが、インモデル戦略のゴールです。
「SEO不要論」は誤解——変わるのは「目的」
インモデル戦略を聞いて「もうSEOはいらないのか」と感じた方もいるかもしれません。
しかし、それは誤解です。
従来のSEO(ランキング獲得・被リンク獲得・技術的最適化)は、インモデル化を支える基盤として
引き続き機能します。AIが学習するデータの多くは、依然としてインターネット上の公開コンテンツです。
つまり「Webに存在すること」「信頼性の高いサイトとして評価されていること」は、
インモデル化の前提条件でもあります。
変わるのは「何のためにSEOをするか」という目的意識です。ランキング1位を取ることが目的ではなく、
AIがあなたの専門性や独自知識を「当然の知識」として吸収するための環境を整えること。
これがこれからのSEOの本質になります。
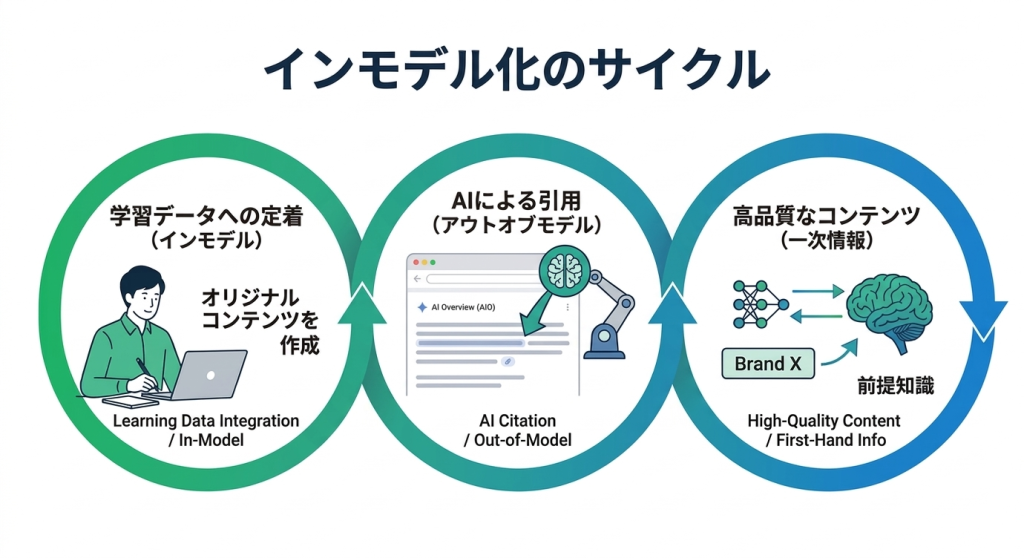
第3章:「引用」のその先のゼロクリック——なぜ頑張るほど損をするのか
良質なコンテンツほどAIに要約されてしまう
整理されたコンテンツはAIにとって最高の素材です。これを別の角度から見ると、
SEOのベストプラクティスに従えば従うほど、AIがあなたのサイトを要約して
答えを出しやすくなるという逆説が生まれます。
SparkToro社の2024年調査が示す「外部サイトへのクリック36%」という現実は、
まだ序の口に過ぎません。本当に恐ろしいのは、この「クリックの奪い合い」が
起きている市場そのものが縮小していくことです。
また米Gartner社は、AI検索の普及により、2026年までに検索ボリューム自体が
25%減少すると予測しています。つまり、「クリックされにくい」上に「検索数自体も減る」という、
二重の兵糧攻めが始まっているのです。これまでの「整理して引用を待つ」だけのSEOは、
もはや縮小していくパイを削り合う、終わりのない消耗戦でしかありません。
参照:米ガートナー社:AIチャットボットやその他の仮想エージェントの影響により、検索エンジンのトラフィックが2026年までに25%減少すると予測
「アルゴリズム」から「AIの学習データ」にターゲットを変える
従来のSEOは「Googleのアルゴリズムに正しく評価してもらう」ことを目的にしてきました。
しかし今後、問うべき問いは変わります。
「このコンテンツは、次世代のAIモデルが学習したときに、どのように記憶されるか?」
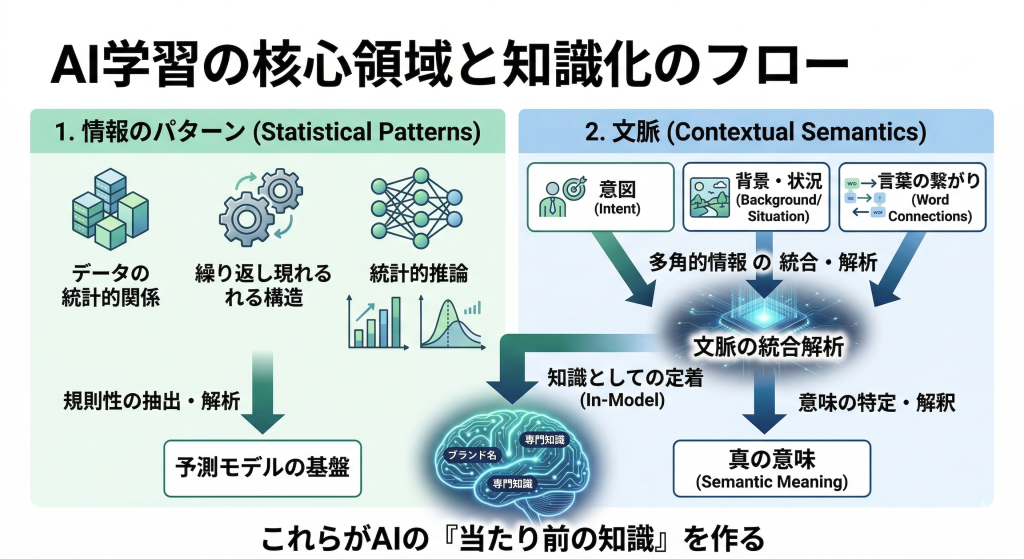
AIが学習するのは主に以下の2つです。
- 情報のパターン
- 文脈(コンテキスト)
100サイトが同じことを書いていれば、それが「常識」として記憶されます。しかし、
あなただけが持つ独自のデータや視点があれば、それは「新しい知識」として
AIに取り込まれる可能性があります。
引用待ちの戦略(アウトオブモデル最適化)は、競合他社も全員が目指している場所です。
そこでの戦いは、
- より速く
- より安く
- より多く
コンテンツを作れた者が有利な消耗戦です。
一方、インモデル戦略は「あなただけの知識」を武器にする戦いです。
独自データ、実測値、誰も試みていない検証——こうした一次情報は、
競合がコピーできない参入障壁になります。
第4章:インモデル戦略の実装手順――ブランドをAIに刻み込む5ステップ
ステップ1:ターゲットの「悩み」と「ブランド」を結ぶ文脈設計
インモデル戦略の出発点は、
「あなたのブランドがどんな文脈で語られるべきか」を明確に定義することです。
AIは特定のキーワードと特定の情報を「セット」で記憶します。
例えば「渋谷 パーソナルジム 女性 初心者」というクエリに対して、
あなたのブランドが連想される文脈を設計するということです。
そのためには、まず自社が「誰の、どんな課題に対して、どのような独自の解決策を持っているか」を
言語化する必要があります。
文脈設計の実践としては、まず競合が使っていない切り口を探します。
例えば競合が「選び方5つのポイント」を書いているなら、
あなたは「実際に50人にインタビューして分かった、失敗するパターン3つ」を書く。
この「独自の切り口」の積み重ねが、AIが特定の文脈であなたを連想するための素地になります。
※失敗例:「〇〇とは」「〇〇のメリット・デメリット」といった、よくあるコンテンツを大量に作っても、
文脈設計にはなりません。すでに100サイトが同じことを書いているからです。
【補足データ:海外SEOメディアの分析】
米国の権威あるSEOメディア『Search Engine Land』の分析でも、Googleの「AI Overviews」
において特定のブランドが推奨される基準は、従来のリンク数以上に
クエリとエンティティ(ブランド)の関連性の深さ」が重視されていることが指摘されています。
参照:米ガートナー社:AIチャットボットやその他の仮想エージェントの影響により、検索エンジンのトラフィックが2026年までに25%減少すると予測
ステップ2:AIが学習したくなる「一次情報(独自データ)」の生成
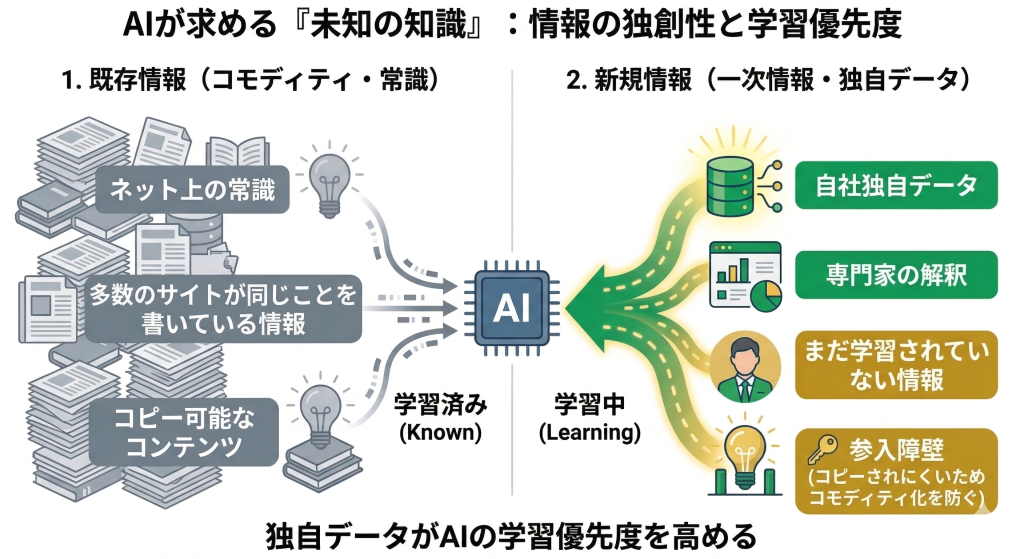
AIが最も価値を置くのは、ネット上の常識に存在しない情報です。具体的には以下のものが有効です。
- 自社サービスや商品の実測値・検証データ
(例:「当社製品をA/Bテストした結果、コンバージョン率が38%向上した」) - 顧客や業界へのアンケート・インタビューの結果
- ツールを使った大規模な調査データ
- 業界の専門家としての独自の解釈や予測
この「一次情報」は、公開するだけでなく、明確に「自社が発信源である」ことを示すことが重要です。
「〇〇社調べ」「〇〇独自調査」という形でブランドと紐づけることで、AIがその情報をあなたのブランドと
結びつけて記憶しやすくなります。
ステップ3:AIに正しく認識させるため「構造化データ」による実体の定義
AIに「あなたが何者か」を正確に認識させるためには、
Schema.orgを用いた構造化データの実装が有効です(詳細は次章で解説します)。
ポイントは、ブランド名・URL・SNSアカウント・創業者情報・専門領域をひとつの
データとして紐づけること。
これにより、AIの知識グラフの中で「この組織はこの領域の専門家である」という文脈が形成されます。
ステップ4:複数チャネルを横断したサイテーション(言及)の獲得
インモデル化を加速させるには、自社サイトだけでなく、外部の信頼性の高いメディアやプラットフォームで
ブランドが言及される状態を作ることが有効です。
業界メディアへの寄稿、ポッドキャストへの出演、専門的なフォーラムでの発信——こうした活動は、
従来の被リンク獲得と似ているように見えますが、目的が異なります。
ランキングを上げるためではなく、AIの学習データが
「このブランドは複数の文脈で専門家として登場する」と認識するための文脈の蓄積です。
ステップ5:AIの回答をモニタリングし、属性(タグ)を微調整する
インモデル戦略は実施して終わりではなく、継続的な検証が必要です。
具体的には以下を定期的に確認します。
- ChatGPT・Geminiなどの生成AIに、自社ブランド名や専門領域に関するクエリを入力したとき、
どのように言及されるか - AI回答の中で、競合と比較してどのような文脈で自社が登場するか(または登場しないか)
- 新たに発信した一次情報が、数ヶ月後にAI回答の中に反映されているか
現時点では、AIのインモデルへの介入度合いを正確に測る指標は確立されていません。
しかし、AI回答の質的なモニタリングを継続することで、
自社の文脈設計が正しく機能しているかを検証することができます。
第5章:AIへの「公式な名刺」――構造化データの戦略的活用
なぜ構造化データがAIへの「名刺」になるのか
例えば、あなたが異業種交流会に参加したとき、口頭で自己紹介するより名刺を渡す方が、
相手の記憶に正確に残りやすい。Schema.orgを用いた構造化データは、
AIに対してまさにその役割を果たします。
AIやGoogleの知識グラフ(ナレッジグラフ)は、Webページのテキストを読む際に
「どの情報がどの主語(エンティティ)に属するか」を構造的に理解しようとします。
構造化データはその解釈を助け、「この情報はこの組織のものだ」という紐づけを確実にします。
構造化データ初心者向けの最低限設定2つ
インモデル戦略の観点から、まず実装すべきは以下の2つです。
① Organization(組織)スキーマ
組織名、URL、ロゴ、設立年、所在地、連絡先などの基本情報をまとめたものです。
AIはこれを参照することで「この組織はどんな存在か」を把握します。
記述例
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "株式会社〇〇",
"url": "https://example.com",
"logo": "https://example.com/logo.png",
"sameAs": [
"https://twitter.com/example",
"https://www.linkedin.com/company/example",
"https://ja.wikipedia.org/wiki/〇〇"
]
}
</script>上記の記述例のような構造化データをhtml内の<head>内に入れる。WordPressならばテーマのheader.phpに
張り付けもしくはプラグインを使うことで対応します。
*上記は記述例ですので。会社名・URL・logo(絶対パスで記述)については運用しているサイトの情報を
入力してください。また各種SNSのリンクについても同様です。
② sameAsプロパティでブランドの「同一性」を証明する
sameAsプロパティは、同じ組織・人物を指す複数のURLを紐づけるためのものです。
公式サイト・Wikipediaページ・SNSアカウント・Wikidata・Googleビジネスプロフィールなどを
sameAsで繋ぐことで、AIの知識グラフ内での「同一エンティティ」としての認識が強化されます。
Wikipediaページがない場合でも、Wikidataへの登録(無料)は比較的容易で、AI認識の強化に有効です。
構造化データ初心者が最初に取るべき実装手順
構造化データの実装に不慣れな方は、以下の順序で進めることをお勧めします。
- GoogleビジネスプロフィールとSNSアカウントを整備し、情報を統一する
- トップページまたはAboutページにOrganizationスキーマを実装する
- sameAsにGoogleビジネスプロフィール・主要SNS・WikidataのURLを追加する
- Googleのリッチリザルトテストで正しく読み込まれているか確認する
構造化データは検索順位への直接的な影響は限定的とされていますが、
AIが情報の「主語」を正しく認識するための基盤として、今後ますます重要性が増す技術です。
第6章:今日からできる3アクション——AIの「前提知識」になるための最初の一歩
本記事で伝えてきたことを一言で言えば、
「AIに引用されることを待つ時代は終わり、AIに記憶される時代が始まっている」
ということです。
ゼロクリック検索の増加、AI Overviewsの普及、LLMの学習データへの組み込み
これらはすべて同じ方向を示しています。
コンテンツの戦場は「検索結果ページの順位」から「AIの前提知識」へと移行しつつあります。
アクション1:インモデル対策キーワードを特定する
まず、自社が「この文脈では第一想起されるべき」と考えるキーワードを3〜5個書き出してください。
次に、ChatGPTやGeminiでそのキーワードに関連する質問をし、
現時点でAIがどのように回答しているかを確認します。
自社が登場するか、登場するとしたらどんな文脈か——これが現在地の把握です。
アクション2:独自の一次情報コンテンツを1本作る
競合が持っていない、あなただけのデータや検証結果を使ったコンテンツを
1本作ることから始めてください。
アンケート結果でも、実際の顧客の声でも、自社商品の実測値でも構いません。
ネット上の常識をなぞるのではなく、ネット上の常識を「更新する」コンテンツを目指してください。
アクション3:Organizationスキーマを実装する
今すぐトップページにOrganizationスキーマを追加し、sameAsにGoogleビジネスプロフィール・
主要SNSアカウントのURLを記述してください。
これはAIへの「名刺」の第一歩であり、技術的なハードルも低い施策です。
AIが当たり前になった検索環境で生き残るのは、整理された情報を並べるサイトではなく、
AIが「新しいことを教わった」と感じるサイトです。インモデル戦略は、SEOの終焉ではありません。
SEOが進化した先の姿です。あなたが今持っている専門知識と独自の経験こそが、
最強の参入障壁になる時代が来ています。



コメント Comments
コメント一覧
コメントはありません。
トラックバックURL
https://query-craft.jp/ai-in-model-seo/trackback/