
目次(クリックで開く)
海外のWebマーケ情報、どう集めていますか?
以前の自分は、お気に入りの海外メディアを一つずつ開き、読み終えたら次のサイトへ移動する——いわゆる「巡回スタイル」で情報を追っていました。追うサイトが1〜2つなら、それでも十分回せます。
でも、SEO、リスティング広告、GA4、SNS、サイト改善、そして最近はn8nのような自動化の話まで。扱う領域が広がるにつれ、このやり方は音を立てて破綻しました。国内の情報だけでも手一杯なのに、海外の最新トレンドまで追うとなると、見るべきソースは一気に増えます。
その結果、「読む時間」よりも「目的の記事を探して移動する時間」のほうが長くなってしまう。
「あの時読んだ記事、どこだっけ?」
ブックマークを掘り返し、履歴を検索して、また見失う。探しているうちに時間だけが溶けて、本来やるべき施策の手が止まります。体感では毎日30分、週に換算すると3時間以上を、ただ巡回と探索のためだけに消費していました。
せっかく有益な情報に触れても、知識として積み上がらず、指の間からこぼれ落ちていく感覚。**「このままでは、情報のアップデートだけで1日が終わってしまう」**という危機感がありました。さらに、海外の最新トレンドを追い切れていないことが、競合に遅れを取る不安としてじわじわ効いてきます。
この「情報が散在し、制御不能になっている」という違和感こそが、今回の仕組みを作る出発点でした。
理想の状態を「要件」として言語化した
「情報が散在している」と気づいた時点で、情報を追いかけるためだけにサイトを回るのはやめました。まず最初に取り組んだのは、ツール選びではなく、「理想の状態」を要件として言語化することです。
ここが曖昧なままだと、仕組み作りはすぐに迷子になります。自分が求めていたのは、次の3つの状態でした。
1)海外の最新情報を、一括で「自動収集」したい
あちこちのサイトを巡回するのではなく、必要な情報が“勝手に集まってくる状態”。
複数メディアの更新を一箇所で俯瞰できるだけで、情報収集の心理的・時間的コストは劇的に下がります。
2)カテゴリ別に整理し、「知識資産」としてストックしたい
読み流すだけでは、情報は砂のように消えていきます。SEO、広告、GA4、n8n……これらをカテゴリ別に分類し、
後からいつでも検索・再利用できる「ストック型のデータベース」として積み上げたいと考えました。
3)「どこが発信しているか(source)」を明確に残したい
同じテーマでも媒体によって視点は異なります。「どのメディアの主張か」を記録することは、
情報の信頼性を判断する軸になり、マーケターとしての判断精度に直結します。
この3つを満たすには、単にブラウザで記事を読むだけでは不十分でした。
そして、これらの要件を形にしようとした瞬間、海外情報を扱う以上どうしても避けられない壁が立ちはだかります。
——そう、「英語」の壁です。
英語の壁と、「翻訳以前の問題」
海外の一次情報は、そのほとんどが英語です。
最初は、ブラウザの翻訳機能で読めば十分だと思っていました。しかし、機械的な翻訳はどこか不自然で、
「結局なにが言いたいのか」という核心が掴みにくい。大事なニュアンスほど抜け落ちて、読んでいるのに腹落ちしない——
そんな経験は、英語の文章をブラウザで翻訳して読もうとしたことがある人なら、誰もが感じることではないでしょうか?
そこで次に考えたのが、生成AIやDeepLで翻訳の質を上げればいい、という発想です。
「翻訳の精度さえ上がれば、すべて理解できるはずだ」と。
ただ、ここで気づきました。翻訳の精度を上げても、根本的な解決にはならない。
なぜなら、問題の本質は「言語」だけでなく、「情報の断片化」にあったからです。どれだけ綺麗に翻訳できても、
情報の置き場所がバラバラなら、また「あの記事どこだっけ?」と探し回る羽目になります。
これでは、どれだけ時間をかけても学びが資産になりません。
翻訳ツールの前に必要だったのは、情報を一箇所に集約し、いつでも知見を取り出せる“仕組み”でした。
日本語に訳す前に、まず情報を一箇所に集約する。そして、そこで集めたデータを整理(カテゴリ化・source保持・重複排除)してから
翻訳する。この「収集と蓄積」のフローが確立されて初めて、翻訳というプロセスに意味が持ちます。
ここまで整理して、ようやく前段で定義した3つの要件(自動収集/カテゴリ化/source保持)が一本の線に繋がりました。
そして、次の問いが明確になります。「では、どうやって“集める”を自動化するか?」
そこで選んだのが、n8nでした。
まず「集める」を解決したい:n8nを選んだ理由
「情報の断片化」が本質だと分かった以上、最初に解くべき課題は「収集の自動化」でした。
つまり、“サイトにアクセスしてから情報を収集する(探しに行く)”という行為そのものを手放すことです。
自動化ツールは世の中にいくつもありますが、その中で自分が n8n を選んだ理由は、異なるサービス同士を連携するだけでなく、
集めた情報を自分が使える形に“整えられる”自由度が圧倒的で、拡張性を感じたからです。
1)複数ソースの取得〜整形を、一本の流れに集約できる
海外のマーケ情報は、メディアごとにデータ形式がバラバラです。RSSの仕様も違えば、項目の持ち方も異なります。
n8nなら、これらを1つの自動処理の流れ(設計図)としてまとめて扱い、後で扱いやすい“綺麗なデータ”へ変換してから次へ渡せます。
例えば、こんな処理です。
- 必要な項目(タイトル、URLなど)だけを抜き出す
- 日付形式を統一する
- 不要なノイズを除去する(データのクレンジング)
この「整える」工程が自動化できるかどうかが、運用負荷を大きく左右します。
2)変化に追従できる“拡張性”がある
もう一つの理由は、仕組みの拡張のしやすさです。
「今は収集だけでいいけれど、いつかAI要約や翻訳も入れたい」
「重要な更新だけSlack通知したい」
マーケターなら、運用していくうちに必ず次の“欲”が出ます。n8nは、視覚的に部品(ノード)を継ぎ足していけるので、
最初から完璧を目指さず、小さく始めて改善を繰り返す運用に最適でした。
ここまでで「集める」と「整える」の道筋は見えました。
でも、それだけでは仕組みとして完成しません。
整えた情報を、あとから何度でも使える形で積み上げるには、強固な“受け皿(目的地)”が必要です。
次は、その受け皿としてなぜ NotionDB を選んだのかを整理します。
集めた後の置き場所が必要:NotionDBを選んだ理由
n8nで「集める」「整える」までの流れが見えてきても、それだけでは仕組みとして完成しません。
綺麗に整えた情報を受け取り、あとから何度でも使える形で蓄積する。
つまり、強固な「受け皿(目的地)」が必要になります。
自分はその目的地として、Notionのデータベース(NotionDB)を選びました。
理由はシンプルで、「理想の状態を『要件』として言語化した」で掲げた「知識の資産化」という要件に、
NotionDBが最も深く噛み合ったからです。
1)「ストック型」に変えるためのデータベース機能
記事を「読む」だけなら、ブックマークやRSSリーダーでも十分かもしれません。
でも自分が欲しかったのは、「読み流して終わる情報」ではなく、実務で何度も取り出せる知識でした。
NotionDBなら、記事を保存するだけでなく、カテゴリ・source・公開日・URLといった項目(プロパティ)を持たせて管理できます。
同じルールで溜め続けることで、情報は単なるリンクの集合ではなく、価値のある知識資産に変わっていきます。
2)フィルタリングが、そのまま実務のスピードになる
情報が増えるほど重要になるのは、「いかに速く取り出せるか」です。
- SEOカテゴリの海外事例だけを読みたい
- 今週分の中で重要度が高いものだけ抽出したい
- 特定メディア(source)の主張をまとめて確認したい
こうした要望を、フィルタ一つで即座に実現できるのがNotionDBの強みです。
探す時間を減らして、考える時間に変える。 自分が受け皿に求めた本質はここでした。
3)sourceを残し、判断の精度を上げる
同じトレンドでも、発信媒体によって前提や文脈は違います。
sourceを固定して残しておくことで、「どこが、どんな立場で言っているか」を客観的に評価できるようになります。
これは、戦略を練るときの判断のブレを減らす、強力な軸になります。
ここまでで、「n8nで集めて整え、NotionDBに蓄積して資産化する」という土台の設計図が完成しました。
ただ、自分はエンジニアではありません。
次のチャプターでは、この仕組みを非エンジニアの自分がどう形にしていったのか——
そして、その過程で生成AIをどう使ったのかを正直に書きます。
自分はエンジニアじゃない:それでも作りたかった
ここまで読んで、「それ、結局エンジニアじゃないと無理では?」と思った人もいるかもしれません。正直に言えば、自分も最初はまったく同じ不安を抱えていました。自分の本業はWebマーケターです。施策を考え、GA4の数字から仮説を立て、成果に繋げるのが役割。コードを書いてプロダクトを作る人間ではありません。
しかし、情報収集を「仕組み化」しようとした瞬間、一つの壁にぶつかりました。やりたいことを実現するには、APIの仕様、
データ形式の変換、エラー処理……といった**“エンジニア的な思考”**がどうしても避けて通れなかったからです。
正直、ここが一番苦しいポイントでした。
画面上では「部品を繋ぐだけ」に見えるのに、いざ動かすとエラーで止まる。原因が分からないまま時間だけが溶けていく焦燥感。
「マーケターとしての仕事がしたいのに、なぜ自分はここで詰まっているのか」と、足元をすくわれる感覚がありました。
それでも投げ出さなかったのは、これが一度きりの効率化ではなく、今後ずっと自分を助けてくれる「知の土台」になると確信していたからです。一度仕組みを完成させれば、毎日の巡回に奪われていた時間は、すべて「戦略を考える時間」に変わります。小手先の効率化ではなく、
長期的に身につけられる知識として積み上げ、武器にしたかった。
そこで自分が選んだ解決策は、一人で抱え込むのではなく、生成AIを「設計パートナー」にすることでした。
生成AIは、何でも自動で完成させてくれる魔法ではありません。
でも、非エンジニアの自分にとっては、「次に何を考えるべきか」「どこを疑えばエラーが直るのか」を共に紐解いてくれる、
頼れる相棒になりました。
もしあなたが「エンジニアじゃないから」と足を止めているなら、これだけは伝えたい。
完璧に理解してから動く必要はありません。作りながら、AIと一緒に理解していけばいい。
生成AIに依頼して失敗したこと/うまくいった進め方
生成AIを「設計パートナー」にすると決めた当初、自分はかなり楽観していました。
「やりたいことを伝えれば、魔法のように完成形の仕組みを出してくれる」
「クリックを数回、ポチポチと押せば、『これが求めていたアウトプットだよね?』とAIが答えを出してくれる」
正直、そう信じていました。自分が抱えている課題を一瞬で解決してくれる、魔法のアイテムのように。
でも、現実は甘くありませんでした。
失敗:最初から“完成形”を求めて破綻した
当初、生成AIを魔法の杖のように考えていた自分は、頭の中にあるゴール(アウトプット像)を丸ごと渡して、
一気に作らせる方法を選びました。短時間で最大の効果が出るはず……そう思っていたんです。
「海外のWebマーケティングのサイトから情報を収集し、整形して、重複を排除し、NotionDBへ保存する」
この内容のすべてを一度に依頼した結果、仕組みはどんどん巨大化し、途中で制御不能になりました。
ノードが増えるほど前提がズレていき、少し修正するだけで全体が崩れる。
提案は一見それっぽいのに、APIの認証形式やデータの細部が微妙に合わず、原因不明のエラーが多発する。できた設計図を実行すると、
想像とは違うアウトプットが吐き出される。
例えば、重複排除が効かず同じ記事がNotionに増殖するだけで、仕組み全体の信頼性が一気に崩れました。
自分の手でコントロールできない「ブラックボックスの塊」を前に、時間だけが溶けていく……。
心が折れかけました。自分にはn8nを使うことは無理なのか?と。
転換点:ゴールは変えず、「歩幅」を細かくした
n8nで作ってはエラー、直しては別のエラー。気づけば半日以上が溶けていました。
「やっぱり時間をかけてもサイトを巡回するしかないのか?」と、本気で諦めかけた瞬間もあります。
そんなときに気づいたのが、一度に“完成形”を求めるほど、前提がズレて制御不能になるということでした。
そこで、最終ゴールは変えずに、途中のマイルストーンを極限まで細分化しました。
- まず「1つのソース(RSS)を取得する」
- 次に「取得したデータを扱いやすく整える」
- 次に「重複を判定する仕組みを作る」
- 最後に「NotionDBへ保存する」
この進め方に変えた瞬間、霧が晴れました。工程が小さくなるぶん、AIの提案は検証しやすくなり、
不具合が起きても「その一歩」だけを直せば済むようになったからです。
非エンジニアの自分がたどり着いた「依頼の型」
試行錯誤の末、たどり着いた“うまくいく依頼”は、驚くほどシンプルでした。
依頼は「次の一段」だけに絞る:完成形を欲張らない
- 「今の入力データ」の例を渡す:これがないと、AIは想像で答えてしまう
- 「期待する出力形式」を明確にする:欲しい項目や型を先に決めておく
- エラー時は「エラー文」+「現状の構成」をセットで渡す:状況を正確に伝える
生成AIは、目的地まで勝手に運んでくれる自動運転ではありません。
むしろ、地図を一緒に読み解きながら、次の交差点を決める「伴走者」に近い存在です。
この進め方に切り替えてから、自分の仕組みは着実に、かつ強固に積み上がっていきました。
構築した「自動処理の流れ(設計図)」の全体像
ここからは、私が実際に作った「自動処理の流れ(設計図)」の全体像を共有します。
目的は、ノード(部品)の暗記ではありません。情報源が増えても破綻しない“構造”になっているか、そこだけ掴めば十分です。
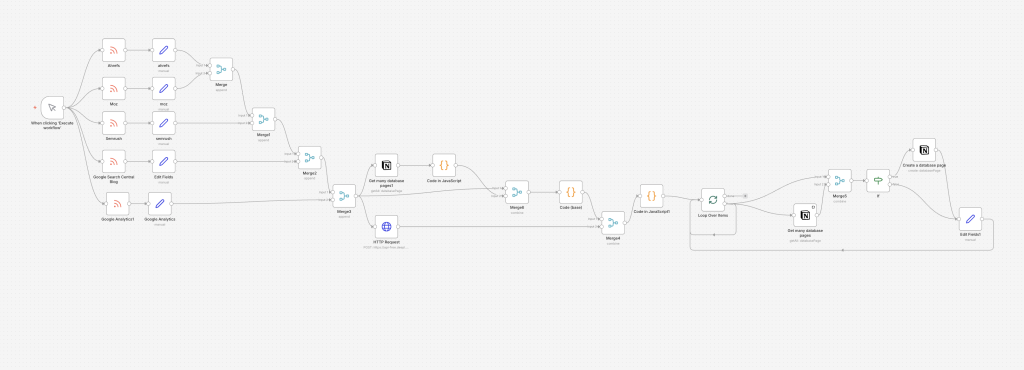
入口:複数ソースから新着を拾う(増えても崩れない入口づくり)
設計図の左側が「入口」です。
Ahrefs / Moz / Semrush / Google Search Central Blog など、複数の情報源から新着を取得しています。
ここで意識したのは、入口が増えても後の処理が崩れないこと。
ソースごとに出てくる項目(タイトルの持ち方、日付、URLなど)は微妙に違うので、取得直後に「Edit Fields(項目の抜き出し)」で、最低限の共通項目に揃えます。
- タイトル
- URL
- 公開日(または取得日)
- source(どのメディアか)
この「最初に揃える」工程があるだけで、後段の整形・判定が一気に安定します。
統合:段階的に一本にまとめる(設計の拡張性を確保する)
入口が複数あると、データはバラバラに流れてきます。
そこで次に、Merge(統合)で段階的に合流させ、一本の流れにまとめています。
この設計のメリットはシンプルで、後からメディアを追加したくなった時に、
- 入口を追加する
- 最低限の項目を揃える
- 既存の合流ポイントに繋ぐ
これだけで済みます。
長期運用を前提にするなら、“増やしても壊れない合流設計”はかなり重要です。
前処理:DBを汚さないための整形(クレンジング)と比較キーづくり
統合した情報は、そのまま保存しません。
保存前に、後で使える形に整えます。ここは「データのクレンジング(洗浄)」の工程です。
たとえば以下のような処理を挟みます。
- 不要なノイズ(余計な文字・改行など)を落とす
- 日付形式の統一(表示揺れをなくす)
- 後段の判定に使うための「比較キー」を作る(例:URL由来のIDなど)
狙いは一つ。
NotionDBを“汚さない”ための前提を、保存前に作っておくことです。
ループ:記事を1件ずつ処理する(止まりにくさを優先する)
次に「Loop Over Items(繰り返し処理)」で、記事を1件ずつ扱う形にしています。
まとめて処理した方が速そうに見えますが、非エンジニア運用だと「速さ」よりも
「止まりにくさ」「原因特定のしやすさ」のほうが効いてきます。
- 1件だけエラーでも、影響範囲を切り分けやすい
- どの記事で止まったかが分かりやすい
- 復旧・修正が局所化できる
運用が続く仕組みにしたかったので、ここは“堅牢性重視”で設計しています。
出力:重複を判定して、NotionDBを聖域に保つ(門番の設計)
最後が、NotionDBへの保存です。
ここが一番こだわったポイントで、闇雲に追加しません。
事前にNotionDB側を参照し、If(条件分岐)で振り分けます。
- 既にある記事:重複として弾く(または必要なら更新)
- 新しい記事:新規ページとして保存する
この「門番」を置くことで、同じ記事が何度も登録されてDBが荒れるのを防げます。
結果としてNotionDBは、**ノイズが少ない“純度の高い知識資産”**として蓄積され続けます。
この設計図で一番伝えたいこと
この仕組みは、プログラミング的な美しさを競うためのものではありません。
一貫して狙ったのは、情報が増えても破綻せず、知識が積み上がる土台を作ることです。
「探す時間」を減らし、マーケターとして本来向き合うべき、戦略設計や施策の実行に時間を戻す。
そのための“レバレッジ”として、この自動化を作りました。
では、この設計図を通って、実際にNotionDBにはどんな項目が溜まり、どう使える形になっているのか。
次は、その受け皿(NotionDB)の中身を見ていきます。
その結果、NotionDBに何が溜まったのか?
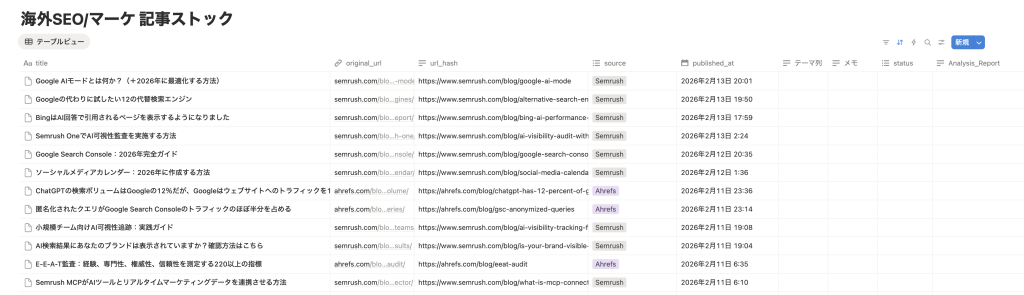
単なるリンク集で終わらせず、**「基本情報」+「鮮度管理」+「自分の視点」+「次のアクション」**の4層で設計しています。
仕組みを支える「背骨」:同定と重複排除
まずは、システムの安定稼働と信頼性を担保するためのプロパティです。
- title:記事のタイトル。一覧で内容を即座に判断する主役です。
- original_url:原文URL。いつでも一次情報に立ち返るための導線です。
- url_hash:【重要】重複判定のキー。URLを元に一意に判定できる値を持たせることで、同じ記事を二度保存してDBを汚す事故を防ぎます。
- source:情報源(Semrush / Ahrefs / Moz / Google Search Central など)。「誰の発信か」を固定することで、情報の信憑性を判断する軸になります。
「鮮度」を操る:published_at
Webマーケティング、特に海外トレンドは鮮度が命です。
published_at(公開日)を正確に同期させることで、「直近1週間のSEOトレンドだけを追う」といった
期間指定のフィルタリングが瞬時にできます。
情報に「血を通わせる」:テーマ列とメモ
ここが「ただのメモ」を「知識資産」に変える核心です。
- テーマ列(カテゴリ):SEO、GA4、AI活用……など、自分の関心軸で分類します。
- メモ:一言でもいいので「自分の解釈」や「施策への転用アイデア」を残します。情報の受取人から、
情報の“活用者”に変わるための場所です。
実務を動かす「作業台」:status と Analysis_Report
このDBが単なるアーカイブで終わらないのは、次の行動を管理しているからです。
- status:「未読」「保留」「ブログネタ」など、情報の処理状況を可視化します。
- Analysis_Report:AI要約や、自分なりの分析レポートの格納先です。
これにより、このDBは「読むための棚」ではなく、「判断し、選別し、アウトプットを生み出す作業台」として機能します。
このDBがもたらした変化
この設計によって変わったのは、「記事が集まる」こと以上に、「探す時間が消えた」ことです。
特定のテーマや情報源から必要な知識を一瞬で引き出せるようになり、情報を探すだけで消耗していた時間が、
本来の仕事である「戦略を練り、施策を打つ時間」へ還元されました。
次は、この土台に「時間」や「お金」を足すと、どこまで自動化を伸ばせるのかを整理します。
拡張性:コストを足すとどこまで自動化できるか
ここまでの仕組みは、極力コストをかけずに「仕組みの土台」を作ることに特化してきました。
ただ正直に言えば、情報収集の自動化は「無料」で始められる一方で、やれることには限界もあります。
このチャプターでは、現在の低コスト構成でできることと、そこに**「時間」や「お金」**というコストを足した先に、どのような未来が広がるのかを整理します。
現状(低コスト構成)でできること
いま最優先しているのは、次の2点に絞った構成です。
- 海外情報を自動収集し、NotionDBにストックする
- 重複を確実に弾き、DBの純度を保つ
この段階だけでも、「自ら情報を探しに行く時間」が消えるという最大級のメリットを得られます。
まずはここを完遂するだけで、仕組み作りの元は十分に取れるはずです。
時間コスト」を足す:マーケターの“眼”を介在させる
お金をかけない代わりに、マーケターとしての「判断」を介在させて運用する方法です。
- 選別:溜まった記事から、重要そうなものだけをピックアップする
- 深掘り:必要な記事のみ、個別にAI翻訳や要約を行う
- 資産化:メモ欄に「自分の解釈」を書き込み、施策やブログのネタへ昇華させる
収集は自動で行い、「選別と解釈」は人間が行う。
これは、本質的な成果を求めるマーケターにとって、極めて合理的で理にかなった運用です。
「金銭コスト」を足す:インプットからアウトプットまでを“流す”
API利用料などのコストを許容すると、インプットからアウトプットまでの距離がさらに縮まります。
- 翻訳の全自動化:取得した記事を即座に翻訳して保存し、ストックされた時点で読める状態にする
- AI要約の自動格納:Analysis_Reportに要点を自動で入れ、「読む前に内容を判断できる」状態を作る
- SNS・通知連携:SlackやXへ自動配信し、チームやフォロワーへ還元する
ただし、これらはあくまで「足し算」です。
土台(収集・整形・重複排除・蓄積)が安定していない状態で拡張すると、運用負荷が跳ね上がり、仕組みが止まりやすくなります。
「インフラ」を足す:24時間稼働の“完全自動”へ
さらに一歩進めるなら、n8nを常時稼働させるサーバー環境(セルフホスト等)を用意することで、
PCを閉じていても仕組みが回り続ける「完全自動」に近づけます。
情報収集が「意識的な作業」から「無意識の習慣」へ変わる。自動化の最終形の一つです。
結局、どこまでやるべきか?
結論はシンプルです。
「まずは『集めて、汚さずに、溜める』ところまでを完璧にする」。
その上で、必要に応じて翻訳や通知を付け足していくのが最も賢明です。
拡張できる「余白」を残しながら、小さく始めて大きく育てる。これこそが、n8n×Notionで仕組みを構築する最大の醍醐味です。
まとめ
海外のWebマーケ情報を追いかけるほど、真の課題は「翻訳の精度」ではなく、「情報の散在」にあると痛感しました。
複数のサイトを巡回しては見失い、探すだけで時間が溶けていく。この状態では、どれほど有益な情報に触れても、
実務の武器(資産)には変わりません。
そこで取り組んだのが、最新情報をn8nで仕組み化し、NotionDBに「汚さず、積み上がる形」で蓄積することでした。
- 複数ソースを一箇所に集約する
- 最低限の形に整える(扱いやすいデータにする)
- 重複を弾いて、DBの純度を保つ
- 後から検索して使える状態で溜め続ける
これだけで「探す時間」は劇的に減り、本来向き合うべき戦略設計や施策の実行に、貴重な時間を戻せるようになります。
完璧さよりも「土台」を優先する
この仕組みは、プログラミングの美しさを競うためのものではありません。非エンジニアでも、目的を細かく分解し、
生成AIを設計パートナーとして使いながら、一歩ずつ積み上げていけます。
重要なのは、最初から全自動の完成形を狙わないこと。まずは 「集めて、汚さずに、溜める」 土台を固める。
ここができて初めて、翻訳・要約・通知・投稿といった拡張が“効く”ようになります。
まずは「1つのソース」から始める
もし今、海外情報の波に疲れているなら、最初の一歩は小さくて十分です。
「特定の1サイトを、自動でNotionDBに溜める」
ここから始めて、運用しながら少しずつ入口を増やしていく。小さく始めて、止まらない形に育てる。
その積み上げが、日々のインプットを確実に成果(施策・ブログ・収益)へつなげる、あなた専用の情報インフラになります。


コメント Comments
コメント一覧
コメントはありません。
トラックバックURL
https://query-craft.jp/n8n-notion-overseas-webmarketing/trackback/