
SEO記事を作成する際、競合上位サイトの見出し分析は、記事構成を考えるうえで重要な作業です。検索結果の上位に表示されているサイトを確認することで、検索意図や記事構成の傾向を把握しやすくなります。
ただ、私の場合はこの確認にかなり時間がかかっていました。タイトル、本文の文字数、H1/H2/H3の見出しタグをページごとに確認していく必要があり、キーワードが変わるたびに同じ作業を繰り返すだけで、かなりの時間を取られていたからです。
本当は競合分析の流れをすべて自動化したかったのですが、いきなりそこまでつなげるのは難しかったので、まずは一番時間がかかっていた確認作業を軽くするところから始めることにしました。今回は、有料ツールの代替を作るのではなく、上位表示されているサイトの構造確認を整理しやすくするために、n8nでWorkflowを組んだ話をまとめます。
なぜSEO競合分析の手作業に時間がかかるのか
SEO競合分析では、上位表示されているサイトをざっと眺めるだけでは足りません。どんなタイトルを付けているのか、どれくらいの情報量で書かれているのか、どのような見出し構成で展開しているのかまで確認してはじめて、上位記事の傾向が見えてきます。
問題は、この確認を手作業で続けると想像以上に時間がかかることです。1サイトだけなら何とかなりますが、上位記事を何本も並べて比較しようとすると負担は一気に増えます。しかも、これを1キーワードだけで終わらせるわけではなく、別のキーワードでも同じように繰り返すことになるので、記事設計に入る前の段階でかなりの時間を使ってしまいます。
特にきつかったのは、確認する項目自体はそこまで複雑ではないのに、本数が増えると一気に時間を持っていかれることでした。タイトル、本文の文字数、見出しタグ。1本ずつ見れば単純な作業でも、比較対象が増えると手間は一気に積み上がります。
記事設計のために必要な確認なのに、その確認だけで時間を使いすぎてしまう。だからこそ今回は、競合分析全体を一気に自動化するのではなく、まずはこの重い確認工程を整理しやすくするところから手を付けることにしました。
確認した3つの項目:タイトル・本文の文字数・見出しタグ
今回のWorkflowで整理したのは、タイトル、本文の文字数、そしてH1/H2/H3の見出しタグです。競合分析で確認したい情報はさまざまありますが、今回は上位表示されているサイトがどのような構造で情報を整理しているのかを把握しやすくするために、この3つに絞りました。
タイトルを確認するのは、そのページが何を主題として打ち出しているのかを見るためです。同じテーマの記事でも、タイトルの付け方を見ると、どの切り口を前面に出しているのかが分かります。上位表示されているサイトを並べて見ていくと、共通して使われている言葉や、逆にあまり使われていない表現も見えやすくなります。
本文の文字数を確認するのは、情報量の目安をつかむためです。文字数が多ければよい、少なければ悪い、という話ではありません。ただ、上位表示されているサイトがどのくらいのボリュームで作られているのかを知っておくと、自分がどの程度まで掘り下げるべきかを考える材料になります。極端に薄いのか、かなり厚めに作られているのか、そのレンジ感を把握しておくだけでも違います。
見出しタグを確認するのは、記事の構成を把握するためです。H1/H2/H3の見出しタグを見ていくと、そのページがどんな順番で話を進めているのか、どの論点を大きく扱っているのかが見えてきます。特にH2やH3を比較すると、上位表示されているサイトに共通している論点と、記事ごとに違う部分が見えやすくなります。
この3つが一覧で見られるだけでも、1本ずつページを開いて確認するより比較しやすくなり、記事設計に入る前の下準備もかなり進めやすくなります。
Workflowの全体像
今回のWorkflowは、上位表示されているサイトのタイトル、本文の文字数、見出しタグを比較しやすい形に整理することを目的に組みました。競合分析そのものをすべて自動化するのではなく、1本ずつページを開いて確認する重い作業を少し進めやすくする、というのが出発点です。
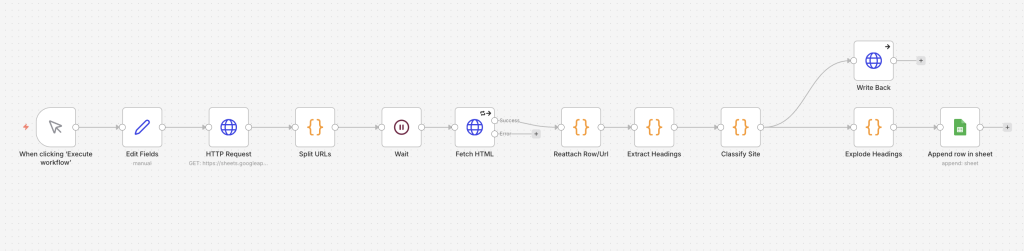
流れとしては大きく4段階です。
- 分析対象となるURL一覧を用意する
- 各URLのHTMLを取得する
- HTMLの中から、タイトル・本文の文字数・見出しタグを抽出する
- 抽出した内容をスプレッドシートへ整理して戻す
やっていること自体はシンプルですが、この形にすることで、手作業では散らばりやすかった確認項目を並べて見られるようになります。
最初から複雑なことをやろうとしすぎなかったことが、今回うまくいった理由のひとつだと思っています。検索結果から上位URLを取得するところまで含めて全部つなげたい気持ちもありましたが、そこまで広げると作る側も運用する側も重くなります。だから今回は「URL一覧がある前提」で、その先の確認工程を整理するところに絞りました。
URL一覧を用意する

最初に必要なのは、分析対象となるURL一覧です。今回は、検索結果の上位に表示されているサイトのURLをスプレッドシートにまとめ、その一覧を入口にしています。このWorkflowは何もない状態からすべてを作るのではなく、分析したい対象URLが並んでいることを前提に動きます。
検索結果からURLを取得するところまで含めると、作り込みの範囲が一気に広がります。今回はそこまでを無理に含めず、まずはURL一覧の先にある構造確認の工程を整理することを優先しました。
HTMLを取得する

Workflowの全体像は、クリックすると拡大して確認できます。まずは全体の流れをつかんでから、このあと各工程を順番に見ていきます。
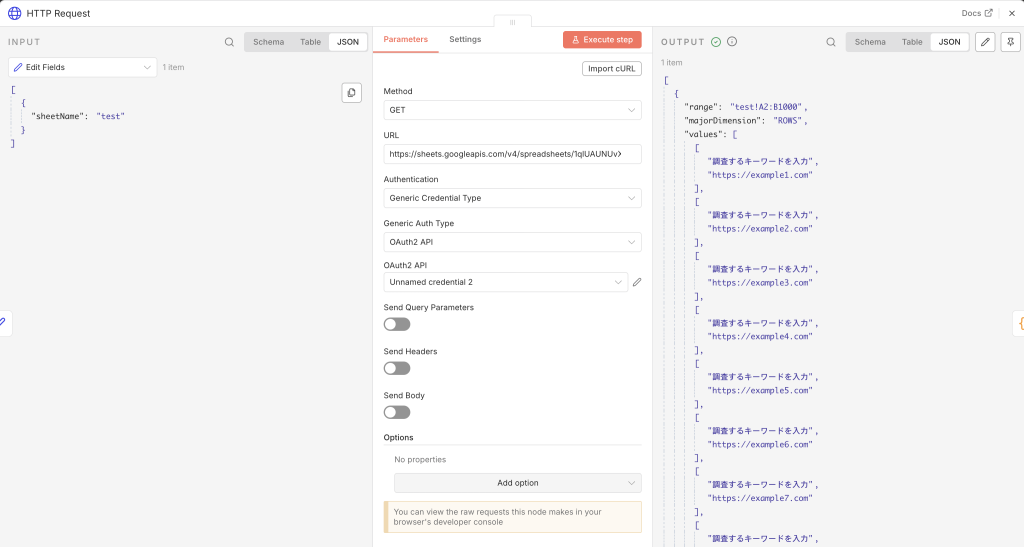
URL一覧が用意できたら、各URLのHTMLを取得します。タイトルも見出しタグも本文の文字数も、元をたどればページのHTMLから拾う情報です。この段階で各ページの中身を取得できないと、その後の抽出処理は進みません。
人がブラウザでページを見るのではなく、後続の処理が扱いやすい形でデータを取ることがポイントです。n8nの中で次の処理につなげられる形にするために、HTML取得の工程が土台になります。
必要な項目だけを抽出する

HTMLを取得したあと、その中から必要な項目だけを抜き出します。今回対象にしたのは、タイトル、本文の文字数、H1/H2/H3の見出しタグです。取れる情報を増やすことよりも、あとで比較しやすい項目に絞ることを意識しました。必要以上に情報を広げると、一覧化したあとに見づらくなるからです。
スプレッドシートに整理する
抽出した情報は、最後にスプレッドシートへ整理して戻します。タイトル、本文の文字数、見出しタグが並ぶことで、上位表示されているサイト同士を比較しやすくなります。1本ずつページを開いて確認するのに比べると、視点を固定したまま見られるので、負担がかなり減ります。
今回のWorkflowは、最終的にこの一覧を作ることが大きな目的でした。n8nの中で完結させることよりも、あとで自分が見返しやすく、記事設計に使いやすい形で情報を残すことを優先しています。
n8nで組んだ各処理の役割
ここではもう少し中に入って、各処理がどんな役割を持っているのかを見ていきます。今回のWorkflowはノード数だけ見ると少し多く見えますが、役割ごとに分けると内容自体はそれほど複雑ではありません。
大きく分けると、URL一覧を読む処理、HTML取得の処理、タイトルと見出しタグを抽出する処理、本文の文字数を整理する処理、スプレッドシートへ書き戻す処理の5つです。今回は後から修正や追加がしやすいように、取得・抽出・整理・書き戻しをある程度分けた構成にしました。
URLを読む処理
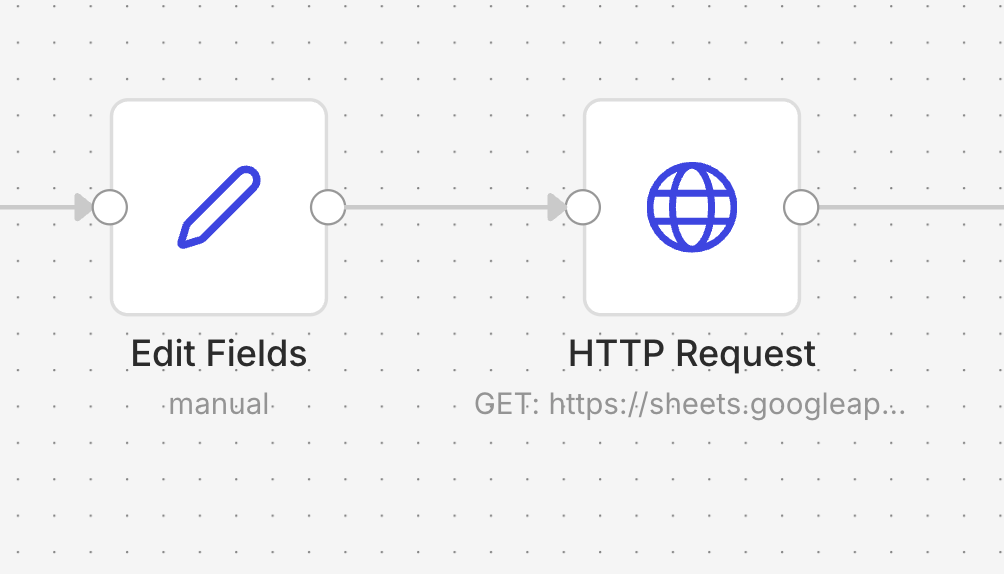
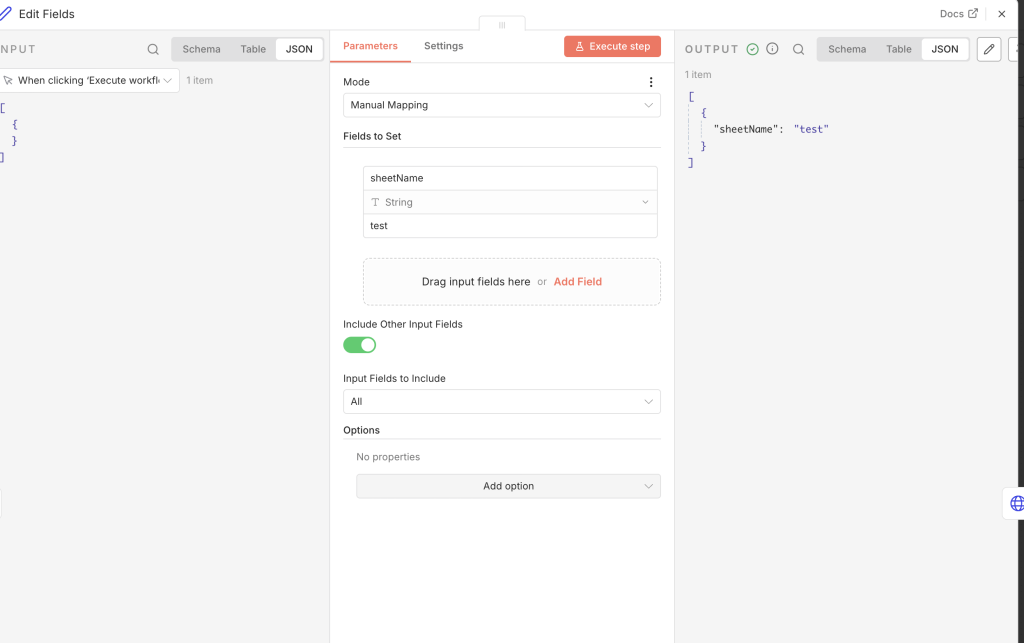
Edit Fields では、後続の処理で使う前提条件をここで整えています。今回は スプレッドシートのシート名 に test を指定し、どのシートを読み込むかを明示しています。
最初の役割は、分析対象となるURL一覧を読み込むことです。今回はスプレッドシートにまとめたURL一覧を入口にしているので、この処理が起点になります。
一見すると単純な工程ですが、どのシートを見ているのか、どの範囲を読んでいるのか、必要な列を取れているのかがずれると後ろが全部ずれます。この工程は単なる読み込みではなく、Workflow全体の前提を揃える役割を持っています。
HTMLを取得する処理
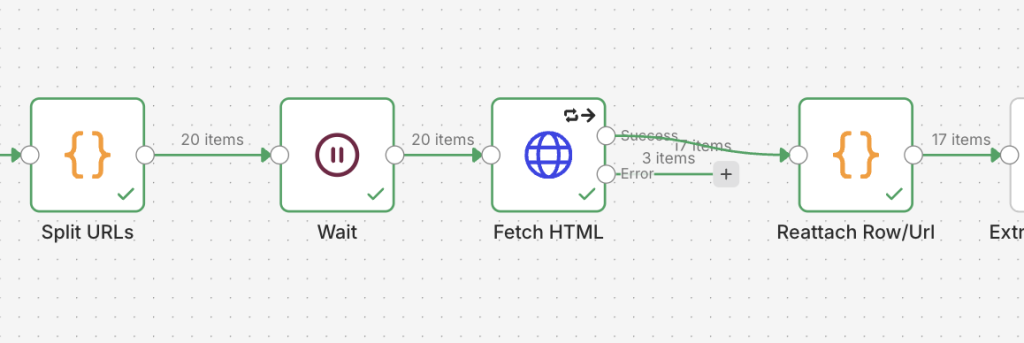
URL一覧を読んだあとは、各URLごとにHTMLを取得します。タイトル、本文の文字数、H1/H2/H3の見出しタグは最終的にはページのHTMLから取る情報なので、この段階が抽出処理の土台になります。人がブラウザでページを見るのではなく、後ろの処理につなげられる形で中身を取ることがポイントです。
タイトルと見出しタグを抽出する処理
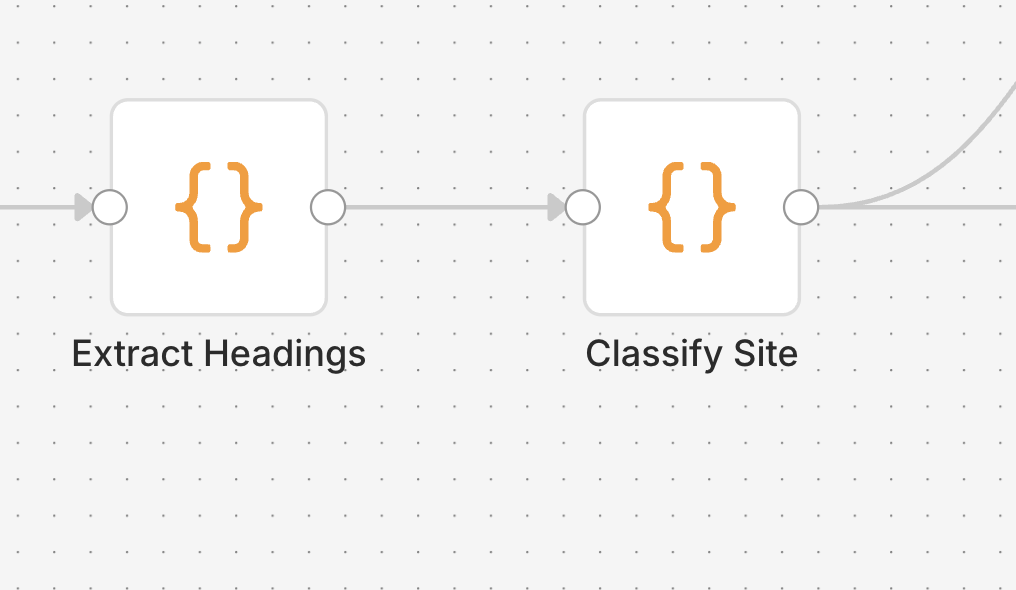
HTMLを取得したあとに行うのが、タイトルと見出しタグの抽出です。タイトルタグからはそのページが何を前面に出しているのかが分かり、H1/H2/H3の見出しタグからは、どの論点を大きく扱い、どの順番で話を進めているのかが見えてきます。
特に見出しタグは、上位表示されているサイト同士を並べたときに差が見えやすい部分です。共通している論点もあれば、特定のサイトだけが大きく扱っている項目もあります。この処理は単にデータを抜き出すためではなく、競合サイトの構造を比較しやすい状態に変えるための役割を持っています。
本文文字数を整理する処理
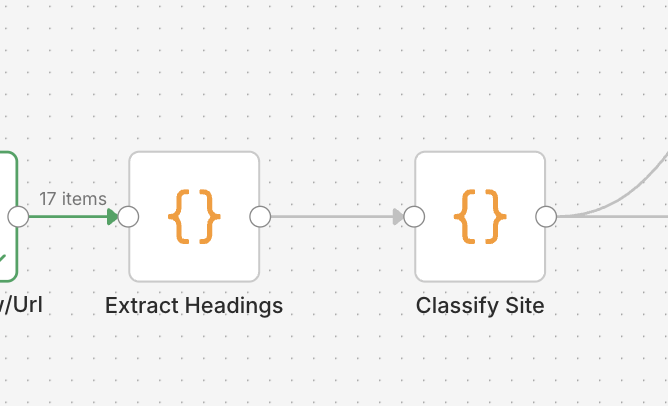

画像だけではコードをそのままコピーしにくいため、Extract Headings ノードで使っているJS全文も下に掲載します。
function decodeHtml(s) {
return (s || "")
.replace(/ /g, " ")
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, '"')
.replace(/'/g, "'");
}
function stripTags(s) {
return (s || "").replace(/<[^>]*>/g, " ");
}
function pickHeadings(html, tag) {
const re = new RegExp(`<${tag}[^>]*>([\\s\\S]*?)<\\/${tag}>`, "gi");
const out = [];
let m;
while ((m = re.exec(html)) !== null) {
const text = decodeHtml(stripTags(m[1])).replace(/\s+/g, " ").trim();
if (text) out.push(text);
}
return out;
}
// footer 抽出(footerタグ or よくあるID/class)
function pickFooterText(html) {
const candidates = [
/<footer[^>]*>([\s\S]*?)<\/footer>/gi,
/<(div|section)[^>]*(id|class)=["'][^"']*(footer|site-footer|global-footer)[^"']*["'][^>]*>([\s\S]*?)<\/\1>/gi,
];
for (const re of candidates) {
const m = re.exec(html);
if (m) {
const raw = m[m.length - 1];
return decodeHtml(stripTags(raw)).replace(/\s+/g, " ").trim();
}
}
return "";
}
// ★ここが重要:Reattachでbodyに入れたHTMLを最優先で読む
const html = $json.body ?? $json.decoded_html ?? $json.data ?? $json.text ?? "";
const safeHtml = (html || "").toString();
// title
const titleMatch = safeHtml.match(/<title[^>]*>([\s\S]*?)<\/title>/i);
const title = titleMatch ? decodeHtml(stripTags(titleMatch[1])).trim() : "";
// headings
const h1 = pickHeadings(safeHtml, "h1");
const h2 = pickHeadings(safeHtml, "h2");
const h3 = pickHeadings(safeHtml, "h3");
// main text char count
const mainText = decodeHtml(stripTags(safeHtml)).replace(/\s+/g, " ").trim();
const mainCharCount = mainText.length;
// footer
const footerText = pickFooterText(safeHtml);
return {
json: {
run_id: $json.run_id ?? "",
url: $json.url ?? "",
row: $json.row ?? null,
title,
mainCharCount,
h1: h1.join("\n"),
h2: h2.join("\n"),
h3: h3.join("\n"),
footerText,
},
};
見出しタグとあわせて確認したかったのが、本文の文字数です。単純に多い少ないを判断したいわけではなく、上位表示されているサイトがどれくらいの情報量で作られているのかをざっくり把握するために見ています。
極端に薄いのか、かなり厚めに作られているのか。そのレンジ感があるだけでも、記事設計の前提はかなり立てやすくなります。見出しタグだけでなく本文の文字数もあわせて整理することで、上位表示されているサイトの構造をもう少し立体的に見られるようにしています。
スプレッドシートへ書き戻す処理
最後の役割は、抽出した内容をスプレッドシートへ書き戻すことです。n8nの中だけで処理が完結しても、後から比較しづらければ使いにくいため、最終的に自分が見返しやすい形で残しておくことを優先しました。この工程は単なる出力ではなく、競合分析の下準備を比較しやすい形に変えるための出口として、大事な役割を持っています。
作成時に困ったポイント
今回のWorkflowは、最初からスムーズに動いたわけではありません。全体の流れ自体はシンプルでも、実際に作ってみると細かい部分でいくつかつまずきました。特に大きかったのは、認証まわり、参照先のズレ、取得範囲のズレ、書き戻し先のズレです。
こうした問題は1つずつ見ると単純に見えますが、Workflowの途中でどこか1か所でもずれると後ろの処理が全部おかしくなるので、原因の切り分けに時間がかかります。抽出処理そのものより、前提条件が正しく揃っているかを確認するところで時間を使った、というのが正直な感想です。
認証が切れていて、最初の処理が進まなかった
最初に困ったのは認証まわりです。n8n側では接続されているように見えていても、実際にはOAuth認証の再接続が必要になっていることがありました。見た目では問題がなさそうでも、実行するとエラーになって止まるので、最初は処理のロジックが原因なのか認証が原因なのかの切り分けに手間取りました。
Google Sheetsとの接続やHTTP Requestで外部データを扱うWorkflowでは、認証が切れているだけで入口の処理が止まります。しかも見た目上は接続済みに見えることもあるので、まず認証状態を疑う必要があると感じました。
参照しているスプレッドシートが想定とずれていた
次に大きかったのが、どのスプレッドシートを参照しているのかがずれていたことです。n8n側では正常に処理が進んでいるように見えても、実際には別のスプレッドシートを見ていたため、今開いているシートには何も反映されない、という状況が起きました。
処理が失敗しているわけではないので特に分かりにくいです。n8n上では成功しているのに期待した場所に結果が出ていないと、最初は抽出や書き戻しのロジックを疑いたくなります。実際には参照先そのものがずれていただけでした。どのファイルを読んでいて、どのファイルに戻しているのかを最初に確認しておくことの重要性を実感しました。
取得する範囲がずれていて、必要なデータを正しく読めていなかった
取得範囲のズレも、分かりにくかったポイントです。URLだけを取っているつもりでも、必要な列が不足していたり、逆に想定外のデータを読んでいたりすると、その後の処理でずれが広がります。
今回も、読み込んでいる範囲が正しくないことで、意図したデータではなく古いデータや別のデータが流れてしまう場面がありました。スプレッドシートを入口にしているWorkflowでは、どのシートのどの列をどこまで読むのかを明確にしておかないと、後続の処理が不安定になりやすいです。
書き戻し先がずれていて、結果が見えなかった
もう1つ困ったのが、書き戻し先のズレです。抽出処理自体はうまくいっているのに結果が見当たらないときは、書き戻し処理が失敗しているように見えます。ただ実際には、別シートや別ファイルに書いていたというケースでした。
n8n上では成功して見えているのに今見ている場所に結果がないと、どこで問題が起きているのか分かりにくくなります。書き戻し先は「成功したかどうか」だけでなく、「本当に今見たい場所に出ているか」まで確認しないといけないと感じました。
処理そのものより、前提条件を揃えることのほうが大事だった
振り返ると、今回困ったポイントの多くは、抽出ロジックそのものより前提条件が揃っていなかったことにありました。認証が切れていないか、正しいファイルを見ているか、読み込む範囲が合っているか、書き戻し先が合っているか。こうした前提が1つでもずれると、後ろの処理は全部不安定になります。
Workflow作成では「何を抽出するか」だけでなく、「どこから読み、どこへ戻すか」を最初に整理しておくことがかなり重要だと分かりました。処理の難しさ以上に、入口と出口の整合性を揃えることのほうが大切だと感じた場面が多かったです。
このWorkflowをどう記事設計に使うのか
このWorkflowを作った目的は、データを取ること自体ではありません。最終的にやりたかったのは、上位表示されているサイトを比較しやすい形に整理して、記事設計の前段階を少し進めやすくすることです。タイトル、本文の文字数、見出しタグが一覧で見られるようになると、1本ずつページを開いて確認していたときよりも、全体の傾向をかなり掴みやすくなります。
実際に使ってみて特に見やすくなったのは、共通している論点と、記事ごとの差分です。複数のサイトで共通して入っている見出しもあれば、特定のサイトだけが大きく扱っている項目もあります。こうした違いが見えるだけでも、検索結果の中で何が重視されているのかを考えやすくなります。
タイトルを並べると、どの切り口が多いのか、どの言葉がよく使われているのかも見えてきます。同じテーマであっても、タイトルの付け方には傾向があります。そこを見ることで、上位表示されているサイトが何を主題にしているのかを掴みやすくなりますし、自分がどの方向から切り込むべきかを考える材料にもなります。
本文の文字数も、記事設計の前提を考えるうえで役立ちます。極端に薄いのか、かなり厚めに作られているのか。そのレンジ感があるだけでも、自分の記事をどの程度の厚みで設計すべきかを考えやすくなります。
見出しタグは、記事の構成を考えるときに特に使いやすいと感じました。H1/H2/H3を見ていくと、上位表示されているサイトがどの順番でどんな論点を並べているのかが分かります。どの内容を先に置いているのか、どこを深掘りしているのか。こうした流れを見ることで、自分の記事を組み立てるときの土台を考えやすくなります。
大事なのは、そのまま真似することではありません。共通している論点を把握したうえで、自分はどこを補うのか、どこを整理し直すのか、どこをより分かりやすくするのかを考える必要があります。このWorkflowは「答えを出す仕組み」ではなく、「比較しやすい材料を揃える仕組み」だと考えています。
このWorkflowでできること、できないこと、今後の改善点
今回のWorkflowでできるのは、上位表示されているサイトのタイトル、本文の文字数、見出しタグを整理し、比較しやすい形にまとめることです。1本ずつページを開いて確認していたときに比べると、確認項目が散らばりにくくなり、記事設計の前段階はかなり進めやすくなりました。
ただし、できることには限界もあります。このWorkflowは、競合分析のすべてを自動化するものではありません。実際にその内容をどう解釈するか、どの論点を自分の記事に入れるか、どこを差別化するかといった判断は、最終的には自分で行う必要があります。
有料のSEOツールの完全な代替にもなりません。今回のWorkflowは、そうした高機能なツールの代わりを作ることを目指したものではなく、手作業だと時間がかかりすぎていた確認工程を少し軽くすることに目的を置いています。
また、現状ではまだ手作業が残っている部分もあります。分析対象となるURL一覧は自分で用意しているため、検索結果から上位URLを取得するところまでは自動化できていません。タイトル、本文の文字数、見出しタグを整理する工程は軽くできましたが、URLを拾ってくる工程は今後の課題です。
本当はこの部分まで含めて全部自動化したい気持ちはあります。ただ、いきなりそこまで広げると作成時も運用時も負荷が増えます。だから今回は、まず一番時間がかかっていた構造確認の工程を整理するところに絞りました。今後、検索結果から対象URLを取得する部分までつなげられると、競合分析の下準備はさらに進めやすくなるはずです。
今回のWorkflowは完成形ではなく、まずは時間がかかっていた確認工程を少し軽くするための土台です。全部を一度に自動化するのではなく、時間がかかっていた工程から順番に整理していく。その最初の形としては、十分意味のあるWorkflowになったと感じています。


コメント Comments
コメント一覧
コメントはありません。
トラックバックURL
https://query-craft.jp/seo-competitor-analysis-n8n/trackback/